Column Mapping داینامیک در SSIS با استفاده از کلاس SqlBulkCopy دربرابر Data Flow Task
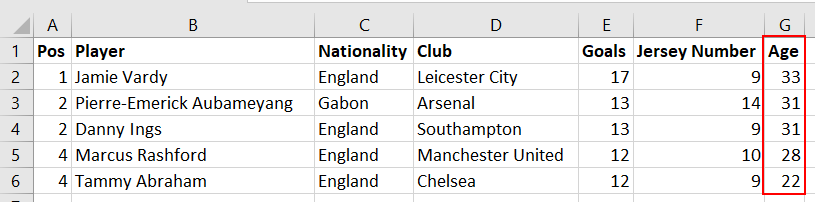
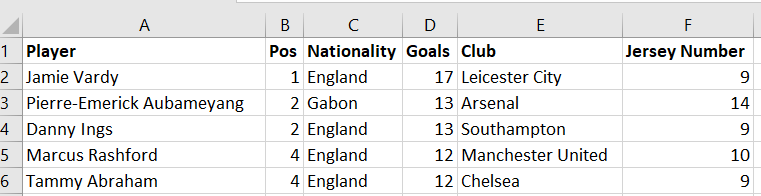
(Data Flow Task) یک جزء ضروری در SQL Server (SSIS) است، زیرا به توسعهدهندگان SSIS ETL این امکان را میدهد که به راحتی دادهها را از منابع داده مختلف استخراج کنند؛ تبدیلهای دادهای اولیه و فازی تا تبدیلهای پیشرفته را انجام دهند؛ و دادهها را به انبار داده منتقل کنند. با این حال، با تمام محبوبیت و راحتی آن، مواردی وجود دارد که DFT به اندازه کافی خوب نیست. برای نشان دادن برخی از محدودیتهای DFT، لیستی تصادفی از گلزنان برتر لیگ برتر برای فصل 2019-2020 در یک فایل داریم.
Pos | Player | Nationality | Club | Goals | Jersey Number |
1 | Jamie Vardy | England | Leicester City | 17 | 9 |
2 | Pierre-Emerick Aubameyang | Gabon | Arsenal | 13 | 14 |
2 | Danny Ings | England | Southampton | 13 | 9 |
4 | Marcus Rashford | England | Manchester United | 12 | 10 |
4 | Tammy Abraham | England | Chelsea | 12 | 9 |
اسکریپت زیر تعریفی از یک جدول SQL Server را نشان میدهد که برای ذخیره دادههای وارد شده از رکوردهای فایل بالا استفاده خواهد شد.
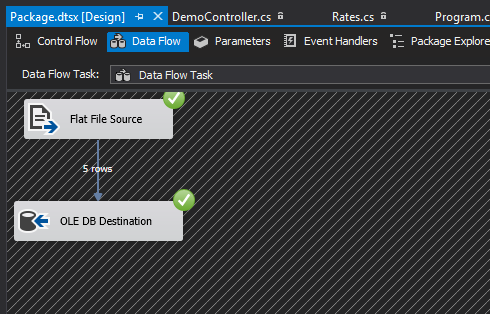

نگاشت داینامیک ستون منبع با مقصد با استفاده از کلاس SqlBulkCopy
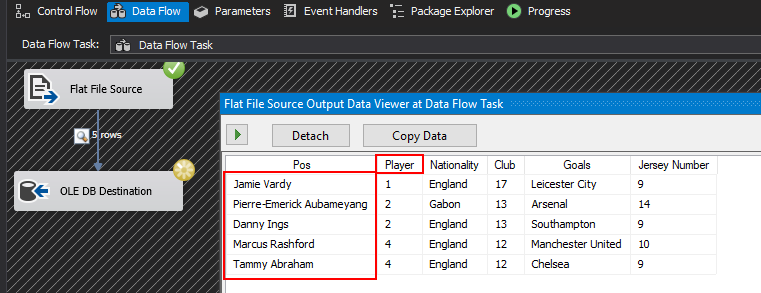
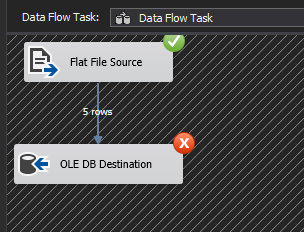
محدودیت Data Flow Task که در بالا نشان داده شد، به راحتی با استفاده از کلاس SqlBulkCopy قابل حل است. همانطور که احتمالاً حدس زدهاید، کلاس SqlBulkCopy شامل جایگزینی Data Flow Task شما با یک اسکریپت .Net است که سپس میتواند از طریق یک Script Task در SSIS اجرا شود. 3 جزء اصلی برای وارد کردن موفقیتآمیز دادههای شما با استفاده از کلاس SqlBulkCopy وجود دارد.
1.تعریف کانکشن ها
همانند پیکربندی یک connection manager در Data Flow Task، کلاس SqlBulkCopy مستلزم آن است که شما اتصالات منبع و مقصد را مشخص کنید. دو متغیر محلی تعریف می کنیم که یک connection string به یک پایگاه داده SQL Server و همچنین مسیری به محل ذخیره فایل منبع CSV ما را مشخص میکنند.
var xyz = @”Data Source=(local)\SQL17DEV;Initial Catalog=DemoDB;Integrated Security=SSPI;”; var x = @”C:\Sifiso\pl_leading_goalscorers.csv”; GetDataTabletFromCSVFile(x, xyz);
2.شیء DataTable خود را آماده کنید.
در مرحله بعد، یک شیء DataTable مطابق کد زیر میسازیم که برای ذخیره دادهها در زمان اجرا استفاده خواهد شد. در این مثال، نقش DataTable مشابه Data Flow Task در SSIS است، با این حال، یک مزیت قابل توجه این واقعیت است که DataTable یک شیء حافظه است که در زمان اجرا ایجاد شده و در پایان اجرا حذف میشود – هرگز مانند Data Flow Task پایدار نمیماند. این بدان معناست که نگاشتهای ستون منبع به مقصد DataTable همیشه هر بار که شیء DataTable ایجاد میشود، بهروزرسانی میشوند، که این یک مزیت ارزشمند هنگام کار با یک جدول SQL Server یا فلت فایل با ساختار ستونی است که دائماً در حال تغییر است.
static DataTable GetDataTabletFromCSVFile(string csv_file_path, string connname) { DataTable csvData = new DataTable(); try { using (TextReader csvReader = File.OpenText(csv_file_path)) { string line; while ((line = csvReader.ReadLine()) != null) { string[] items = line.Trim().Split(‘,’); if (csvData.Columns.Count == 0) { for (int i = 0; i < items.Length; i++) { csvData.Columns.Add(new DataColumn(items[i], typeof(string))); } } else { csvData.Rows.Add(items); } } }
3.نوشتن دادهها در جدول SQL Server
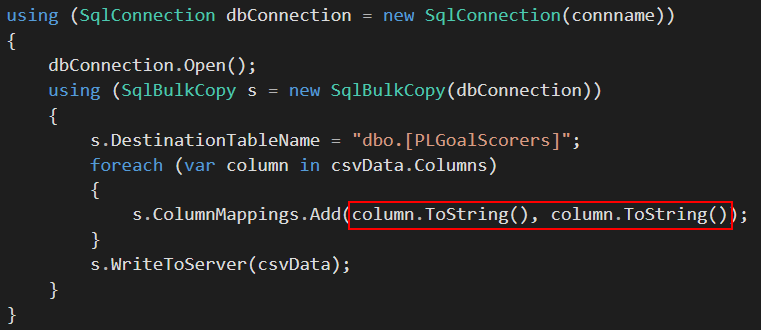
پس از اینکه با موفقیت محتوای مجموعه دادههای منبع خود را در یک DataTable استخراج کردید، میتوانید کلاس SqlBulkCopy را فراخوانی کرده و از آن برای کپی کردن انبوه DataTable در یک جدول SQL Server استفاده کنید. همانطور که در خط 86 در کد زیر نشان داده شده است، متد کلاس SqlBulkCopy که مسئول انتقال واقعی دادهها به SQL Server است، WriteToServer نام دارد و یک DataTable را به عنوان آرگومان دریافت میکند.
using (SqlConnection dbConnection = new SqlConnection(connname)) { dbConnection.Open(); using (SqlBulkCopy s = new SqlBulkCopy(dbConnection)) { s.DestinationTableName = “dbo.[PLGoalScorers]”; foreach (var column in csvData.Columns) { s.ColumnMappings.Add(column.ToString(), column.ToString()); } s.WriteToServer(csvData); }
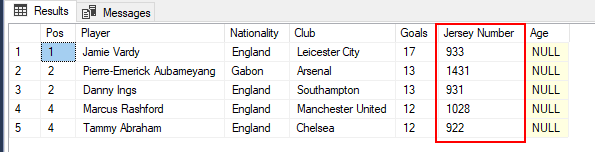
متوجه شدهاید که نگاشت ستون منبع به مقصد در کد بالا در خط 84 پیادهسازی شده است، که در آن هر دو ستون منبع (ورودی) و مقصد (خروجی) به نامهای ستون مشابه نگاشت شدهاند. نگاشت ستونهای ورودی و خروجی به نام ستون یکسان، تنها یکی از چندین گزینه نگاشت ستون موجود در کلاس SqlBulkCopy است. در بخش بعدی، بقیه گزینههای نگاشت ستون موجود در کلاس SqlBulkCopy را بررسی خواهیم کرد.
گزینه های نگاشت ستون SqlBulkCopy Class:
گزینه شماره ۱: نگاشت ستون بر اساس نام
نگاشت یک ستون بر اساس نام، فرض میکند که نام ستون داده شده (مثلاً “Player”) هم در منبع و هم در مقصد وجود دارد. یکی از مزایای این نوع نگاشت این است که لزوماً نیازی به حفظ ترتیب ستونها در هر دو مجموعه داده منبع و مقصد ندارید. شکل زیر نگاشت کلاس SqlBulkCopy از یک ستون بر اساس نام را نشان میدهد.
شکل زیر نشان میدهد که چگونه نگاشت مشخصشده در شکل بالا منجر به اختصاص نام ستون یکسان «Player» به هر دو ستون مقصد و منبع میشود.

یکی از بزرگترین معایب نگاشت ستون بر اساس نام این است که وقتی هیچ تطابق دقیقی روی نام ستون مشخص شده وجود نداشته باشد، با خطای “The ColumnMapping داده شده با هیچ ستونی در منبع یا مقصد مطابقت ندارد” مواجه خواهید شد. سایر مزایا و معایب استفاده از نگاشت ستون بر اساس نام در کلاس SqlBulkCopy به شرح زیر است:
مزایا:
نگاشت ستون بر اساس نام تحت تأثیر موقعیت ستونها قرار نمیگیرد.
معایب:
نگاشت ستون بر اساس نام نیاز به تطابق دقیق روی نام ستون دارد – هرگونه فاصله، کاراکتر پنهان و غیره باعث عدم تطابق نگاشت میشود که منجر به خطای “The ColumnMapping داده شده با هیچ ستونی در منبع یا مقصد مطابقت ندارد” میشود.
گزینه شماره 2: نگاشت ستون بر اساس موقعیت یا شاخص ستون
یکی دیگر از گزینههای نگاشت ستون در کلاس SqlBulkCopy شامل نگاشت ستونهای ورودی و خروجی بر اساس موقعیت یا شاخص ستون است. این رویکرد فرض میکند که ستونهای منبع و مقصد به درستی قرار گرفتهاند. در واقع اگر روش ColumnMappings.Add را پیادهسازی نکنید، این رفتار نگاشت پیشفرض است، همانطور که در کد زیر نشان داده شده است.
using (SqlConnection dbConnection = new SqlConnection(connname)) { dbConnection.Open(); using (SqlBulkCopy s = new SqlBulkCopy(dbConnection)) { s.DestinationTableName = “dbo.[PLGoalScorers]”; foreach (var column in csvData.Columns)
نگاشت موقعیت ستون به ستون در کلاس SqlBulkCopy همچنین این گزینه را برای توسعهدهندگان دارد که با مشخص کردن موقعیت ستونها، نگاشتهای ستون را به طور صریح پیادهسازی کنند. سادهترین پیادهسازی این گزینه نگاشت در شکل زیر نشان داده شده است که در آن یک متغیر محلی اعلان شده و در انتهای هر ترکیب نگاشت ستون، یک واحد افزایش مییابد.
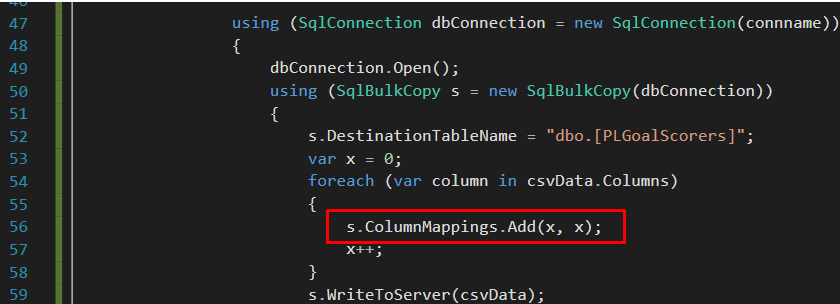
برخلاف گزینه نگاشت ستون بر اساس نام، نگاشت موقعیت ستون بر اساس ستون تحت تأثیر عدم تطابق نام ستونهای ورودی و خروجی قرار نمیگیرد، در عوض، دادهها با موفقیت منتقل میشوند، مشروط بر اینکه انواع دادههای ستون منبع و هدف سازگار باشند. بنابراین، مسئولیت اطمینان از سازگاری موقعیت ستون و انواع دادههای ستونهای منبع و مقصد بر عهده توسعهدهنده است. در غیر این صورت، خطایی مشابه شکل زیر بازگردانده خواهد شد.
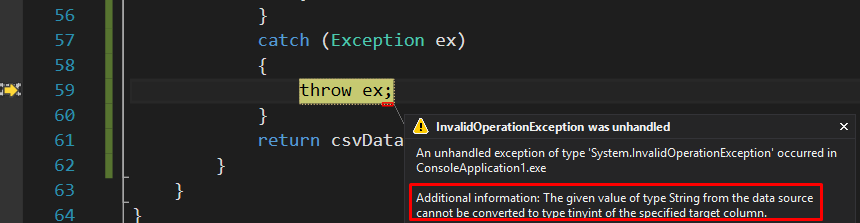
نگاشت موقعیت ستون به ستون مزایا و معایب خاص خود را دارد، همانطور که در زیر نشان داده شده است:
مزایا:
نگاشت موقعیت ستون به ستون تحت تأثیر تغییرات نام ستونها قرار نمیگیرد. نگاشت موقعیت ستون به ستون میتواند به طور خودکار ستونها را بدون مشخص کردن متد ColumnMappings.Add نگاشت کند.
معایب:
ستونهای منبع و مقصد باید به درستی موقعیتیابی شوند.
نیاز به سازگاری نوع داده بین ستونهای منبع و مقصد دارد.
گزینه شماره ۳: ترکیبی از گزینههای Column by Name و Column by Position
یکی دیگر از گزینههای نگاشت ستون که در کلاس SqlBulkCopy در دسترس شماست، استفاده از بهترینهای هر دو حالت است – همانطور که در شکل زیر نشان داده شده است که در آن ستونهای منبع ورودی بر اساس موقعیتشان در برابر نام ستونها در مقصد نگاشت میشوند. این بدان معناست که نام ستونها در مقصد را میتوان بدون نیاز به مرتبسازی مجدد موقعیت ستونها در منبع، تغییر نام داد یا جابجا کرد. این گزینه نگاشت را هنگام کار با منبعی که header ندارد، بسیار مفید خواهید یافت.
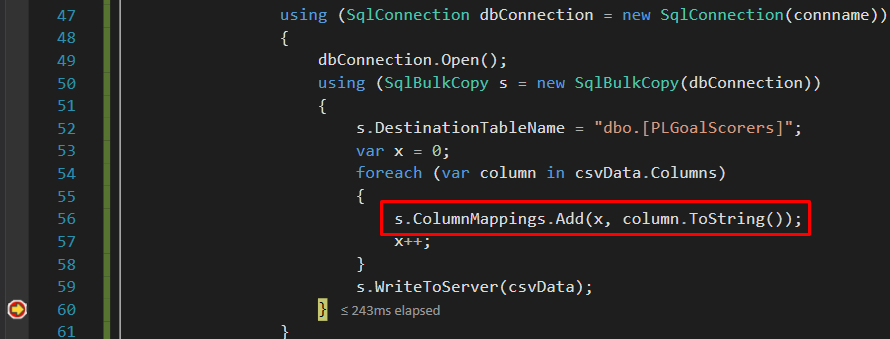
در پایان، وقتی با منبع دادهای سروکار دارید که ساختار آن دائماً در حال تغییر است، استفاده از کلاس SqlBulkCopy را در داخل یک Script Task به جای Data Flow Task در نظر بگیرید. این کار تضمین میکند که میتوانید نگاشتهای ستونی را در زمان اجرا بین منبع و مقصد به صورت پویا ایجاد کنید، بدون اینکه مجبور باشید متادیتای ستون ورودی و خروجی را به صورت دستی بهروزرسانی کنید، همانطور که اغلب در data flow task اتفاق میافتد. یکی دیگر از مزایای استفاده از کلاس SqlBulkCopy این است که سرعت و عملکرد مهاجرت داده بهتری را نسبت به data flow task ارائه میدهد. با این حال، کلاس SqlBulkCopy محدودیتهای خاص خود را دارد:
- کلاس SqlBulkCopy مستلزم آن است که توسعهدهندگان ETL شما مهارتهای برنامهنویسی .Net را کسب کنند.
- کلاس SqlBulkCopy فقط میتواند خروجی خود را در یک جدول SQL Server بنویسد.
- اغلب هنگام کار با کلاس SqlBulkCopy با خطای “The given ColumnMapping does not match up with any column in the source or destination.” مواجه میشوید که در واقع مبهم است.
نظر بگذارید