بهبود Performance با پارتیشن بندی
پارتیشن بندی یک ویژگی SQL Server است که اغلب برای کاهش چالش های مربوط به مدیریت پذیری، وظایف نگهداری یا قفل و مسدود کردن پیاده سازی می شود. مدیریت جداول بزرگ با پارتیشن بندی آسان تر می شود و می تواند مقیاس پذیری و در دسترس بودن را بهبود بخشد. علاوه بر این، یک محصول جانبی پارتیشن بندی می تواند عملکرد پرس و جو را بهبود بخشد. این یک تضمین همیشگی نیست، و دلیل اصلی اجرای پارتیشن بندی نیست، اما وقتی یک جدول بزرگ را پارتیشن بندی می کنید، ارزش بررسی را دارد.
پارتیشن بندی را می توان در طول طراحی اولیه پایگاه داده پیاده سازی کرد، یا می توان آن را پس از اینکه جدول از قبل دارای داده در آن بود، در جای خود قرار داد. بدانید که تغییر جدول موجود با داده ها به جدول پارتیشن بندی شده همیشه سریع و ساده نیست، اما با برنامه ریزی خوب کاملاً امکان پذیر است و فواید آن به سرعت قابل درک است.
جدول پارتیشن بندی شده جدولی است که در آن داده ها بر اساس مقدار یک ستون خاص به ساختارهای فیزیکی کوچکتر تفکیک می شوند (به نام ستون پارتیشن بندی که در تابع پارتیشن تعریف شده است). اگر می خواهید داده ها را بر اساس سال جدا کنید، ممکن است از ستونی از نوع تاریخ مثلا به نام DateSold به عنوان ستون پارتیشن بندی استفاده کنید، و تمام داده های سال 2020 در یک ساختار، همه داده های سال 2019 در ساختار متفاوت و به همین ترتیب… قرار می گیرند. این مجموعه های جداگانه داده ها امکان نگهداری متمرکز را فراهم می کند (مثلا شما می توانید فقط یک پارتیشن از یک ایندکس را rebuild کنید، نه کل ایندکس) و اجازه می دهید داده ها به سرعت اضافه و حذف شوند زیرا می توان آنها را قبل از افزودن یا حذف واقعی به جدول مرحله بندی کرد.
راه اندازی
برای بررسی تفاوت در عملکرد پرس و جو برای یک جدول پارتیشن بندی شده در مقابل یک جدول پارتیشن بندی نشده، دو نسخه از جدول Sales.SalesOrderHeader از پایگاه داده AdventureWorks2017 ایجاد کردم. جدول غیرپارتیشن بندی شده تنها با یک کلید کلاسترد در SalesOrderID، کلید اولیه سنتی جدول ایجاد شده است. جدول دوم در OrderDate با OrderDate و SalesOrderID به عنوان کلید کلاسترد تقسیم شد و هیچ ایندکس اضافی نداشت. توجه داشته باشید که هنگام تصمیم گیری اینکه از چه ستونی برای پارتیشن بندی استفاده کنید، فاکتورهای متعددی باید در نظر گرفته شود. پارتیشن بندی اغلب، اما مطمئناً نه همیشه، از یک فیلد تاریخ برای تعیین مرزهای پارتیشن استفاده می کند. به این ترتیب، OrderDate برای این مثال انتخاب شد و از کوئری های نمونه برای شبیه سازی فعالیت های معمولی در برابر جدول SalesOrderHeader استفاده شد. عبارات ایجاد و پر کردن هر دو جدول را می توانید از اینجا دانلود کنید.
پس از ایجاد جداول و افزودن داده ها، ایندکس های موجود تأیید شد و سپس آمار با FULLSCAN به روز شد:
EXEC sp_helpindex ‘Sales.Big_SalesOrderHeader’;
GO
EXEC sp_helpindex ‘Sales.Part_SalesOrderHeader’;
GO
UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN;
GO
UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN;
GO
SELECT
sch.name + ‘.’ + so.name AS [Table],
ss.name AS [Statistic],
sp.last_updated AS [Stats Last Updated],
sp.rows AS [Rows],
sp.rows_sampled AS [Rows Sampled],
sp.modification_counter AS [Row Modifications]
FROM sys.stats AS ss
INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id]
INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id]
OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp
WHERE so.[object_id] IN (OBJECT_ID(N’Sales.Big_SalesOrderHeader’), OBJECT_ID(N’Sales.Part_SalesOrderHeader’))
AND ss.stats_id = 1;
علاوه بر این، هر دو جدول دارای توزیع دقیق یکسانی از داده ها و حداقل Fragmentation هستند.
عملکرد برای یک پرس و جو ساده
قبل از اینکه هر ایندکس اضافی اضافه شود، یک کوئری اصلی را برای هر دو جدول جهت محاسبه مجموع کسب شده توسط فروشنده برای سفارشات ارسال شده در دسامبر 2017 اجرا میکنیم:
SELECT [SalesPersonID], SUM([TotalDue])FROM [Sales].[Big_SalesOrderHeader]WHERE [OrderDate] BETWEEN ‘2017-12-01’ AND ‘2017-12-31’GROUP BY [SalesPersonID];
GO
SELECT [SalesPersonID], SUM([TotalDue])FROM [Sales].[Part_SalesOrderHeader]WHERE [OrderDate] BETWEEN ‘2017-12-01’ AND ‘2017-12-31’GROUP BY [SalesPersonID];
GO
آمار:
STATISTICS IO OUTPUT
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Big_SalesOrderHeader’. Scan count 9, logical reads 2710440, physical reads 2226, read-ahead reads 2658769, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Part_SalesOrderHeader’. Scan count 9, logical reads 248128, physical reads 3, read-ahead reads 245030, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.

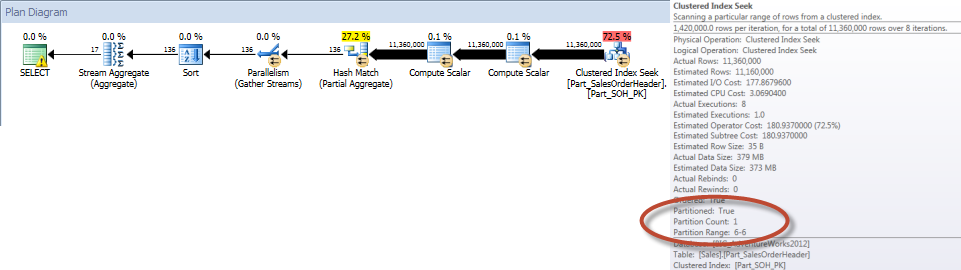
همانطور که انتظار می رفت، پرس و جو در برابر جدول غیرپارتیشن بندی شده مجبورشد یک اسکن کامل از جدول را انجام بدهد زیرا هیچ ایندکسی برای پشتیبانی از آن وجود نداشت. در مقابل، پرس و جو در برابر جدول پارتیشن بندی شده فقط برای دسترسی به یک پارتیشن از جدول نیاز داشت.
اگر منصفانه باشیم، اگر این کوئری به طور مکرر با محدوده های تاریخی مختلف اجرا می شد، باید ایندکس نان کلاسترد مناسب داشته باشد. مثلا:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID]ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
با ایجاد این ایندکس، زمانی که پرس و جو دوباره اجرا می شود، آمار I/O کاهش می یابد و پلن برای استفاده از ایندکس nonclustered تغییر می کند:

با یک ایندکس پشتیبان، پرس و جو در برابر Sales.Big_SalesOrderHeader به تعداد قابل توجهی خواندن کمتر از اسکن ایندکس کلاسترد در برابر Sales.Part_SalesOrderHeader نیاز دارد، که غیرمنتظره نیست زیرا ایندکس کلاسترد بسیار بزرگتر است. اگر یک ایندکس نان کلاسترد قابل مقایسه برای Sales.Part_SalesOrderHeader ایجاد کنیم، اعداد I/O مشابهی را می بینیم:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID]ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);
آمار:
STATISTICS IO OUTPUT
Table ‘Part_SalesOrderHeader’. Scan count 9, logical reads 42894, physical reads 1, read-ahead reads 42378, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
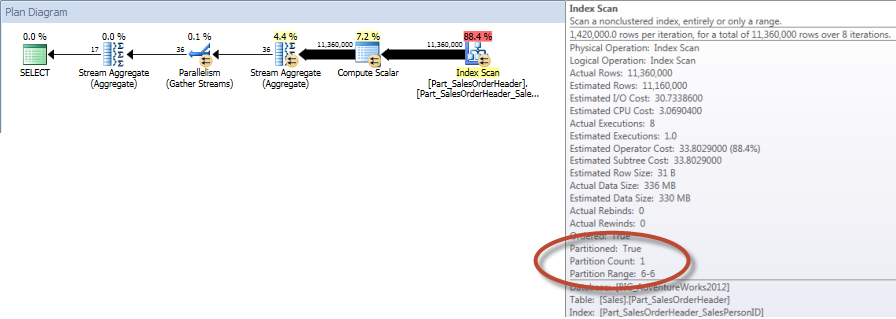
و اگر به ویژگی های Index Scan نان کلاسترد نگاه کنیم، می توانیم تأیید کنیم که موتور فقط به یک پارتیشن دسترسی داشته است (6).
همانطور که در ابتدا گفته شد، پارتیشن بندی معمولا برای بهبود عملکرد اجرا نمی شود. در مثال نشان داده شده در بالا، پرس و جو در برابر جدول پارتیشن بندی شده تا زمانی که ایندکس نان کلاسترد مناسب وجود داشته باشد، عملکرد قابل توجه بهتری ندارد.
عملکرد برای یک پرس و جو موقت
یک پرس و جو در برابر جدول پارتیشن بندی شده می تواند در برخی موارد از همان پرس و جو در برابر جدول غیرپارتیشن بندی شده بهتر عمل کند، برای مثال زمانی که پرس و جو باید از کلاسترد ایندکس استفاده کند. در حالی که ایده آل است که اکثر پرس و جوها توسط ایندکسهای نان کلاسترد پشتیبانی شوند، برخی از سیستم ها پرس و جوهای ad-hoc را به کاربران اجازه می دهند، و برخی دیگر پرس و جوهایی دارند که ممکن است به ندرت اجرا شوند که ایندکسهای پشتیبانی را تضمین نکنند. در مقابل جدول SalesOrderHeader، یک کاربر ممکن است پرس و جوی زیر را برای یافتن سفارشهایی از دسامبر 2017 که باید تا پایان سال ارسال میشد، برای مجموعه خاصی از مشتریان و با TotalDue بیشتر از 1000 دلار، انجام دهد:
SELECT[SalesOrderID],[OrderDate],[DueDate],[ShipDate],[AccountNumber],[CustomerID],[SalesPersonID],[SubTotal],[TotalDue]FROM [Sales].[Big_SalesOrderHeader]WHERE [TotalDue] > 1000AND [CustomerID] BETWEEN 10000 AND 20000AND [OrderDate] BETWEEN ‘2017-12-01’ AND ‘2017-12-31’AND [DueDate] < ‘2017-12-31’AND [ShipDate] > ‘2017-12-31’;GO SELECT[SalesOrderID],[OrderDate],[DueDate],[ShipDate],[AccountNumber],[CustomerID],[SalesPersonID],[SubTotal],[TotalDue]FROM [Sales].[Part_SalesOrderHeader]WHERE [TotalDue] > 1000AND [CustomerID] BETWEEN 10000 AND 20000AND [OrderDate] BETWEEN ‘2017-12-01’ AND ‘2017-12-31’AND [DueDate] < ‘2017-12-31’AND [ShipDate] > ‘2017-12-31’;
GO
آمار:
STATISTICS IO OUTPUT
Table ‘Big_SalesOrderHeader’. Scan count 9, logical reads 2711220, physical reads 8386, read-ahead reads 2662400, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Part_SalesOrderHeader’. Scan count 9, logical reads 248128, physical reads 0, read-ahead reads 243792, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
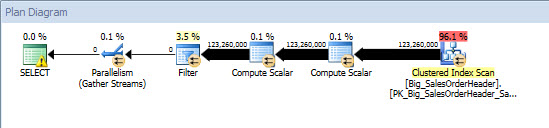
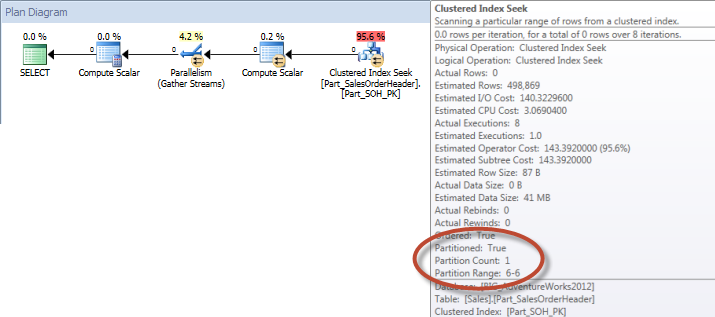
نظر بگذارید